TL;DR:
- Ear training in language improves the ability to perceive phonemes, stress, rhythm, and intonation before speaking. It builds necessary auditory skills through focused, repetitive practice, which enhances pronunciation and listening comprehension. Regular ear training, especially with techniques like shadowing and minimal pairs, accelerates language learning and speech naturalness.
Ear training in language is the structured practice of perceiving phonological elements, including phonemes, stress, rhythm, and intonation, before attempting to reproduce them. The formal term for this process is auditory or phonetic training, and it is the foundation of native-like pronunciation and real listening comprehension. Without it, learners often spend months drilling words they cannot yet accurately hear. Tools like English Accent Coach and platforms like Singwithcanary use this principle directly, building perception skills before pushing learners into production.
What is ear training in language learning?
Ear training for language learners is the deliberate development of your ability to detect and distinguish the sound patterns of a target language. It is not passive listening. It is focused, repeated exposure designed to build new auditory categories in your brain.

The concept borrows directly from music education. In music, relative pitch is developable at any age through consistent practice. The same principle applies to language. You do not need perfect pitch or a musical gift. You need repetition and the right structure.
Language ear training targets two main layers of sound. The first is segmentals, which are the individual sounds, or phonemes, of a language. The second is suprasegmentals, which include stress, rhythm, and intonation. Both layers shape how natural and intelligible your speech sounds to a native listener.
Learners who skip this step pay a real price. Premature text-based learning without ear training locks in phonetic errors driven by native language interference. Those errors become habits. Ear training first prevents that pattern from forming.
What phonological skills does ear training develop?
Auditory training builds three distinct categories of phonological skill. Each one contributes differently to your ability to understand and speak a language clearly.
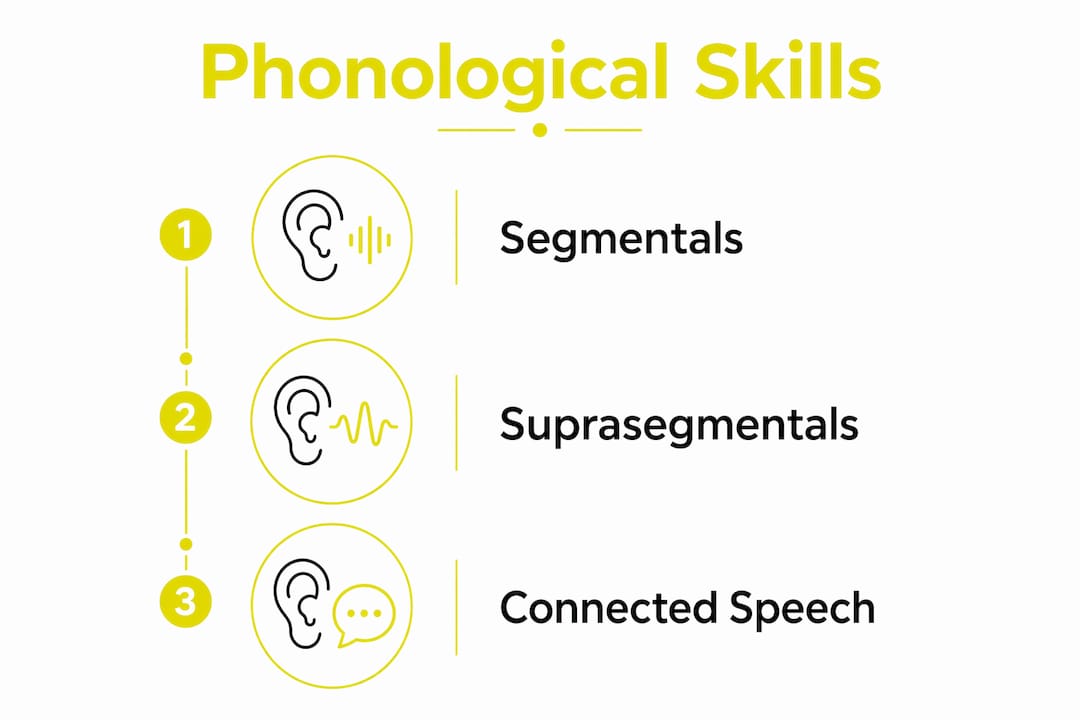
Segmental skills are the most familiar. These involve recognizing individual phonemes and the contrasts between them. English, for example, distinguishes between the vowel sounds in “ship” and “sheep.” Spanish distinguishes between “pero” and “perro.” Learners whose native language does not make these contrasts must train their ears to hear the difference before they can produce it reliably.
Suprasegmental skills cover the music of speech. These include:
- Word stress (which syllable carries emphasis in a word)
- Sentence stress (which words carry the most weight in a phrase)
- Intonation (the rise and fall of pitch across a sentence)
- Rhythm (the timing pattern of stressed and unstressed syllables)
Connected speech features are the third category, and they surprise most learners. In natural, fast speech, sounds do not stay neatly separated. Liaison links the final sound of one word to the opening sound of the next. Elision drops sounds entirely. Assimilation changes a sound based on what surrounds it. French and English both use all three heavily. A learner who has only studied written text will struggle to process real spoken language until they train their ears on these patterns.
Pro Tip: Start your ear training with minimal pairs in your target language. A minimal pair is two words that differ by only one sound, like “bat” and “pat” in English. Drilling these trains your brain to hear contrasts your native language may ignore.
The connection to music ear training is worth noting. Relative auditory discrimination is the skill that underlies both. A musician trains to hear the difference between a major and minor third. A language learner trains to hear the difference between two vowels. The cognitive mechanism is the same.
What are the most effective ear training techniques?
The research on adult phonetic learning points to a clear set of methods. These are not guesses. They are techniques with documented results.
-
High-variability phonetic training (HVPT). HVPT produces measurable gains in both perception and production accuracy. The method exposes learners to the same phoneme spoken by multiple different voices. This forces the brain to build a flexible, speaker-independent sound category rather than a narrow template tied to one voice.
-
Minimal-pair contrast drills. Discrimination must precede articulation for pronunciation training to work. Minimal-pair drills present two similar sounds repeatedly and ask you to identify which one you heard. The goal is not just to know the difference intellectually. The goal is to hear it automatically.
-
Shadowing. Shadowing means listening to a native speaker and repeating what they say with as little delay as possible. Shadowing trains suprasegmental patterns automatically. It forces you to match rhythm, stress, and intonation in real time, which builds the perception-to-production loop faster than any other single method.
-
Focused listening with transcription. Choose a short audio clip of 30–60 seconds. Listen without looking at a transcript. Write down what you hear. Then compare your version to the real text. The gaps reveal exactly which sounds or patterns your ear is missing.
-
Multi-voice exposure. Do not train on one speaker or one accent. Vary your input across genders, ages, and regional accents. This is the core principle behind HVPT and it applies to all your listening practice.
Pro Tip: Keep your daily ear training sessions to 25–30 minutes. Cognitive fatigue from long sessions slows neural pathway formation. Short, consistent sessions build auditory skills faster than occasional marathon practice.
How does ear training improve listening comprehension and pronunciation?
The mechanism behind ear training is neural category building. Every time you hear a new phoneme from multiple speakers and contexts, your brain strengthens the neural pathway associated with that sound. Over time, recognition becomes automatic rather than effortful.
“Pronunciation training is less about mimicry and more about training the ear to identify sounds before reproducing them.”
This matters because your native language has already built strong auditory categories. Those categories actively interfere with new ones. A Japanese learner of English does not fail to hear the difference between “r” and “l” because of a physical limitation. The brain simply routes both sounds into the same existing category. Ear training creates a new category. That is the real work.
The gains are not slow. Phonetic discrimination can improve within one month of structured ear training practice. Learners who train perception first report that pronunciation corrections start to stick in a way they never did before. The reason is simple. You cannot reliably produce a sound you cannot yet hear.
Suprasegmental mastery follows the same path. Once your ear recognizes the stress and intonation patterns of a language, your speech starts to carry the natural melody of that language. Native speakers respond differently to that. They understand you more easily and they engage more naturally. That feedback loop accelerates every other aspect of your learning. You can read more about this connection in the benefits of ear training with music.
How to integrate ear training into your daily routine
The NECTAR daily practice cycle is the most structured framework available for building pronunciation through perception. NECTAR runs 25–30 minutes daily and sequences every step in the correct order.
| NECTAR step | What you do |
|---|---|
| Notice | Listen to native speech and identify a sound or pattern that sounds unclear |
| Ear training | Run focused drills on that specific sound using HVPT or minimal pairs |
| Copy | Shadow the native speaker, matching rhythm and stress as closely as possible |
| Target | Isolate the specific phoneme or pattern and practice it in isolation |
| Articulate | Produce the sound in full sentences with real communicative intent |
| Repeat | Return to the same material the next day to reinforce the neural pathway |
The sequence matters. Skipping straight to articulation without the ear training and copying steps is the most common mistake adult learners make. It produces surface-level mimicry without genuine phonetic understanding.
Technology makes this routine easier to maintain. English Accent Coach provides targeted phoneme drills. Pronunciation dictionaries with audio, like Forvo, let you hear words spoken by real native speakers from multiple regions. Singwithcanary adds a music-based layer, using song lyrics and karaoke to practice pronunciation in context while training your ear on natural speech melody.
Pro Tip: Track your progress by recording yourself once a week reading the same short passage. Compare recordings from week one and week four. The improvement in stress and intonation will be audible, and that evidence keeps you consistent.
Balancing ear training with other skills is straightforward. Spend the first 10 minutes of any study session on pure listening and discrimination work before you open a textbook or grammar app. That sequence primes your auditory system and makes everything else more effective.
Key Takeaways
Ear training in language is the perception-first foundation that makes pronunciation accurate and listening comprehension automatic, and skipping it is the single most common reason adult learners plateau.
| Point | Details |
|---|---|
| Perception before production | Train your ear to hear sounds accurately before attempting to reproduce them. |
| Three phonological layers | Target segmentals, suprasegmentals, and connected speech for complete auditory skill. |
| HVPT and shadowing work | Multi-voice exposure and real-time shadowing produce the fastest measurable gains. |
| Daily short sessions win | 25–30 minutes daily builds neural pathways faster than occasional long study blocks. |
| Progress is measurable | Structured ear training produces noticeable discrimination gains within one month. |
Why most learners train in the wrong order
I have watched hundreds of language learners hit the same wall at the same point. They can read the language reasonably well. They know the grammar rules. But when a native speaker talks at normal speed, they catch maybe half of it. And when they speak, natives wince slightly and ask them to repeat themselves.
The cause is almost always the same. They trained production before perception. They drilled vocabulary with text flashcards before their ears could reliably distinguish the vowel sounds. They practiced speaking before they could hear the stress patterns that make speech sound natural. The result is a learner who has built a pronunciation system on a shaky auditory foundation.
The fix is not complicated, but it requires accepting something uncomfortable. You need to go back to listening before you go forward with speaking. That feels like regression. It is actually the fastest path forward. Learners who commit to even two weeks of perception-first practice, using HVPT drills and shadowing before any production work, consistently report that their pronunciation corrections finally start to stick.
The other thing I have seen work is music. Songs force you to process suprasegmental patterns, the rhythm and melody of a language, in a way that textbooks never do. A learner who has sung along to 50 songs in French has internalized French prosody in a way that grammar drills cannot replicate. That is not a soft claim. It is what the perception-to-production research actually predicts.
— Ben
Singwithcanary makes ear training part of every session
Ear training works best when it is built into a habit you actually enjoy. Singwithcanary learns languages with music by combining song-based listening, karaoke, and vocabulary cards into a single daily practice. Every session trains your ear on real native speech patterns through lyrics, rhythm, and melody.
Singwithcanary’s interactive features include pronunciation quizzes, lyric-based listening exercises, and a global community of learners to practice with. The platform is built for learners who want to build genuine auditory skills without grinding through dry drills. If you want to put the perception-first approach into practice, sign up and start training your ear the way it was designed to learn.
FAQ
What is the difference between ear training and just listening to music?
Ear training is focused, structured practice targeting specific sounds or patterns. Passive music listening builds general familiarity but does not train phoneme discrimination the way deliberate drills do.
How long does it take to see results from ear training?
Phonetic discrimination improves within one month of consistent structured practice. Daily sessions of 25–30 minutes produce faster results than longer, infrequent sessions.
Does ear training work for all languages?
Ear training applies to every language because all languages use phonemes, stress, and intonation. The specific sounds and patterns you target will differ, but the method is universal.
What is auditory training compared to pronunciation practice?
Auditory training focuses on perception, teaching your ear to recognize sounds accurately. Pronunciation practice focuses on production. Effective pronunciation training requires auditory training first.
Can adults develop ear training skills, or is it only for children?
Adults can fully develop ear training skills. Relative auditory discrimination is trainable at any age through consistent practice. The process takes longer than in childhood, but the gains are real and measurable.